





本文介绍了一种新的数据库中间件产品,Mycat,支持MySQL集群或Mariadb cluster,并提供高可用性。Mycat基于cobar,重构网络模块,优化Buffer和Join等基本特性,并兼容绝大多数数据库。
目
录
一、Mycat是什么?
二、Mycat安装
三、MyCat分片
前言
那么大表的数据如何优化呢?
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降
限定数据的范围 例如日期限制在一个月之内
读/写分离
对数据库表进行垂直拆分根据数据库里面数据表的相关性进行拆分。例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表
对数据库表进行水平拆分保持数据表结构不变,通过某种策略对数据进行分片。这样每一片数据分散到不同库中,达到了分布式的目的。水平拆分可以支撑非常大的数据量。
如何实现数据库的水平拆分呢中间件代理:在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。我们现在谈的 Mycat 、360的Atlas、网易的DDB等等都是这种架构的实现。
一、Mycat是什么?
官网:http://www.mycat.org.cn/
Mycat 背后是阿里曾经开源的知名产品——Cobar。Cobar的核心功能和优势是MySQL数据库分片,此产品曾经广为流传,阿里随后开源的 Cobar,并维持到 2013 年年初。Cobar 的思路和实现路径的确不错。基于 Java 开发的,实现了 MySQL 公开的二进制传输协议,巧妙地将自己伪装成一个 MySQL Server,目前市面上绝大多数 MySQL 客户端工具和应用都能兼容。比自己实现一个新的数据库协议要明智的多,因为生态环境在哪里摆着。 Mycat 是基于 cobar 演变而来,对 cobar 的代码进行了彻底的重构,使用 NIO 重构了网络模块,并且优化了 Buffer 内核,增强了聚合,Join 等基本特性,同时兼容绝大多数数据库成为通用的数据库中间件。简单的说,MyCAT是一****个新颖的数据库中间件产品支持 mysql 集群,或者 mariadb cluster,提供高可用性数据分片集群。你可以像使用mysql一样使用mycat。对于开发人员来说根本感觉不到mycat的存在。
支持以下数据库

二、Mycat安装
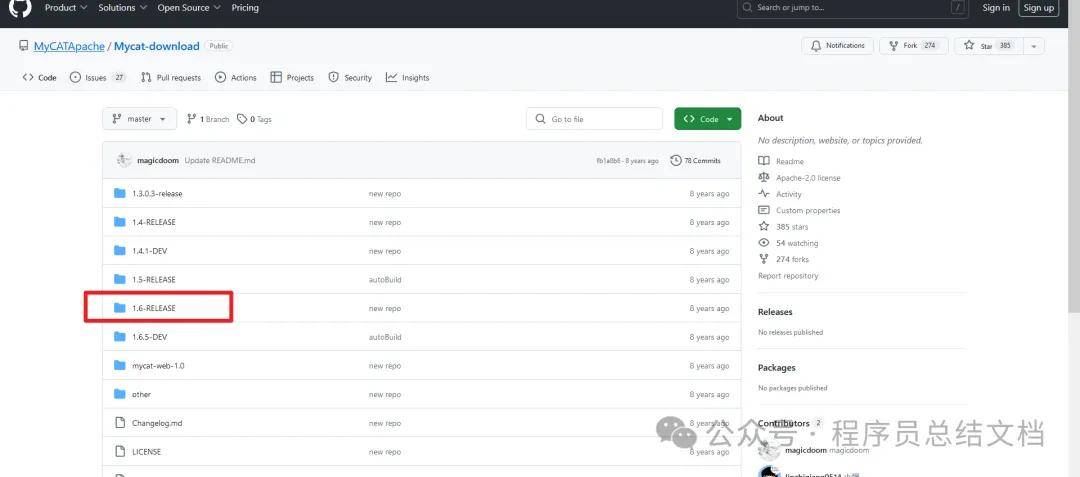
2.1 下载
下载地址:https://github.com/MyCATApache/Mycat-download/
在这里插入图片描述
在这里插入图片描述
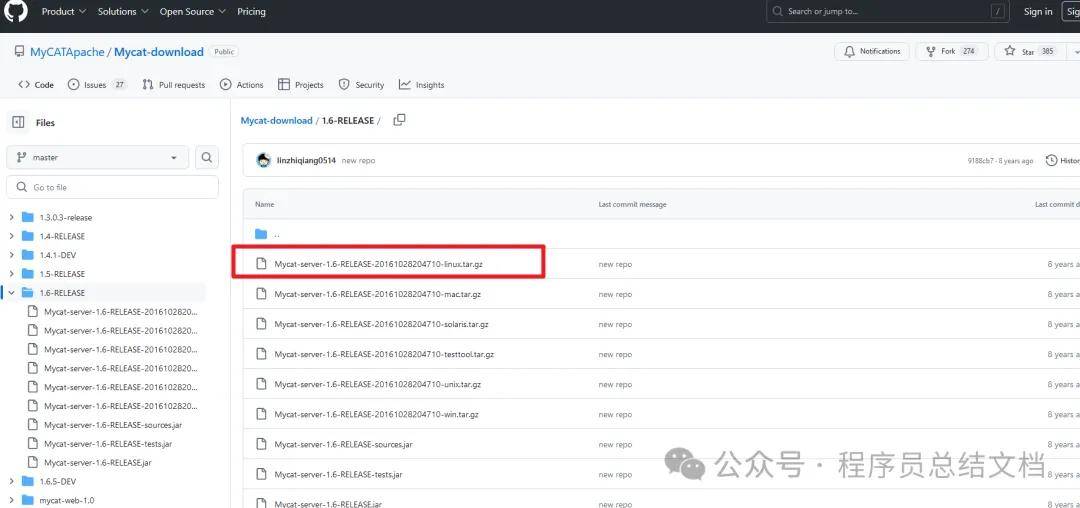
2.2 MyCat的安装及启动
2.2.1上传包到linux解压
Mycat的默认端口号为:8066
# 1、将 Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz 上传至服务器
# 2、将压缩包解压缩。建议将mycat放到/usr/local目录下。
tar -xzvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz -C /usr/local
# 3、进入mycat目录的bin目录,启动mycat
./mycat start
# 4、停止MyCat
./mycat stop
# 5、Mycat的默认端口号为:8066
目录结构为:
2.2.2 启动注意事项
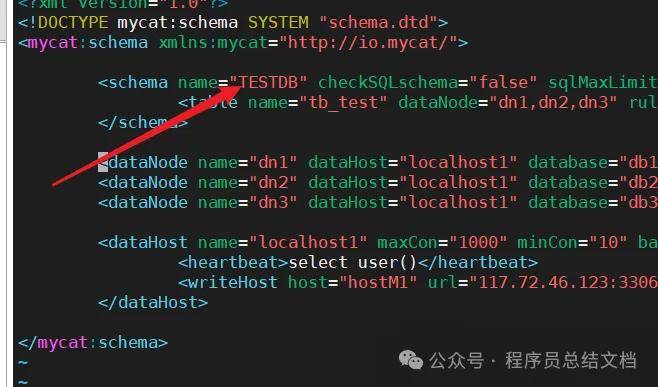
server.xml中的逻辑库和schema.xml中的逻辑库名称对应
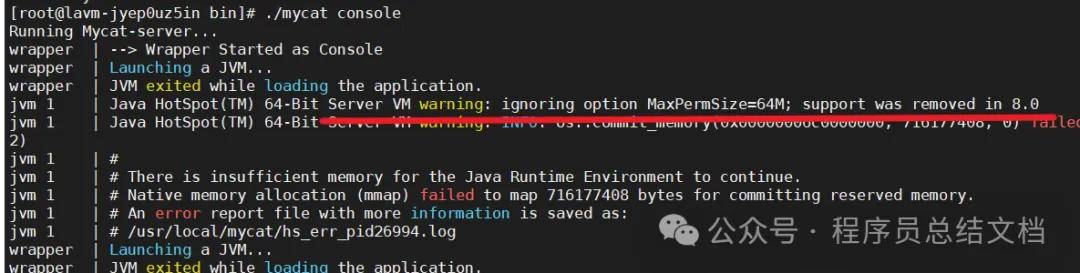
2.2.3 启动失败问题记录
解决Bit Server VM警告:忽略选项MaxPermSize=64M,因为在8.0中已删除 这是由于MaxPermSize=64M选项在8.0版本中被移除了。为了解决这个问题,您可以按照以下步骤进行配置调整:
进入Mycat的配置文件目录:mycat/conf/
编辑wrapper.conf文件,可以使用命令:vim wrapper.conf
定位到wrapper.java.additional.3=-XX:MaxPermSize=64M这一行配置
将该行配置注释掉,改为:#wrapper.java.additional.3=-XX:MaxPermSize=64M
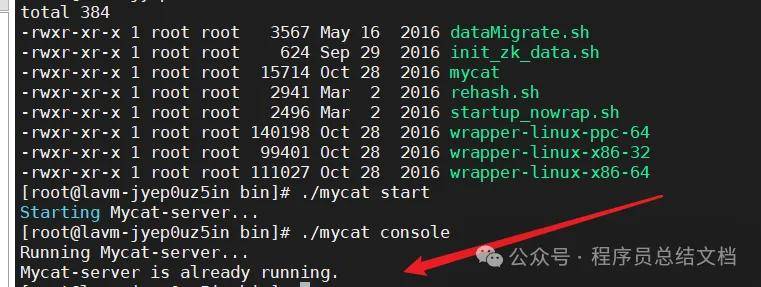
保存文件并从新启动Mycat服务
启动正常
2.2.4 登录MyCat
终端登录
mysql -uroot -p -p27.0.0.1 -P8066
navicat登录

三、MyCat分片
3.1 MyCat架构
1、逻辑库(schema):
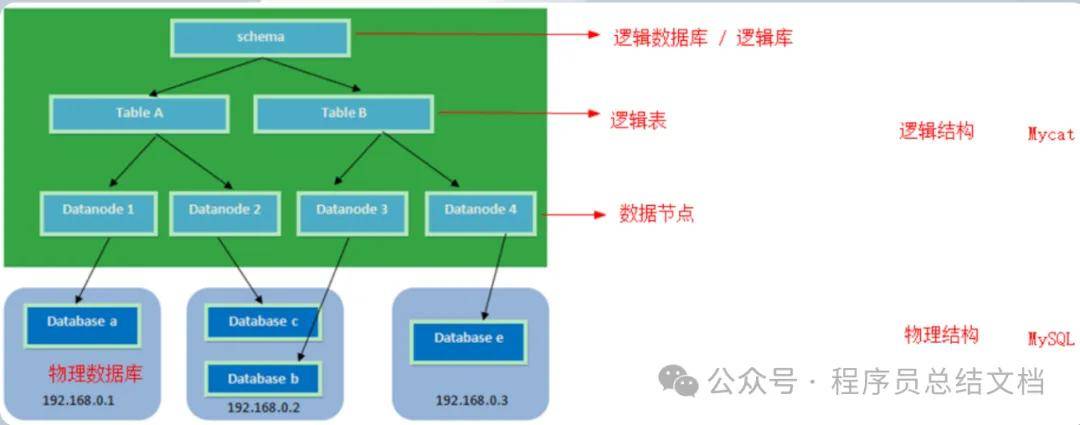
前面一节讲了数据库中间件,通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
2、逻辑表(table):
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
3、分片表:是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。总而言之就是需要进行分片的表。
4、非分片表:一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
5、数据节点(dataNode): 数据节点也被称之为分片节点,数据切分以后,每一个部分就可以被称之为一个分片。每一个分片需要对应一个节点主机。
6、节点主机(dataHost):数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片节点,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
7、分片规则(rule):
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
3.2 分片配置
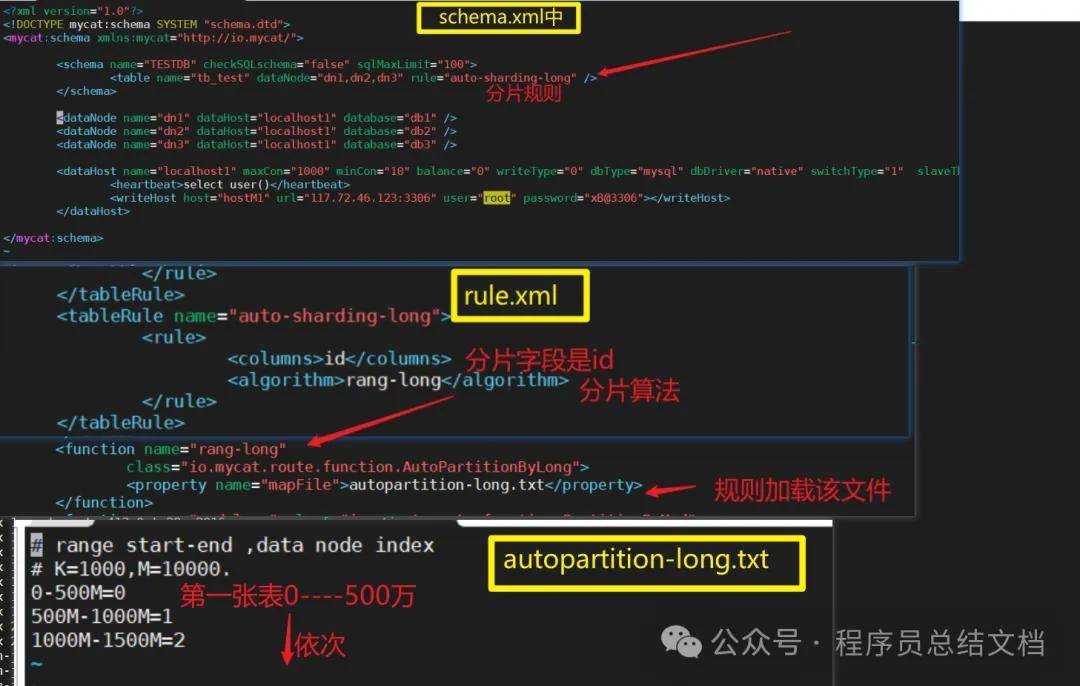
3.2.1 配置文件schema.xml
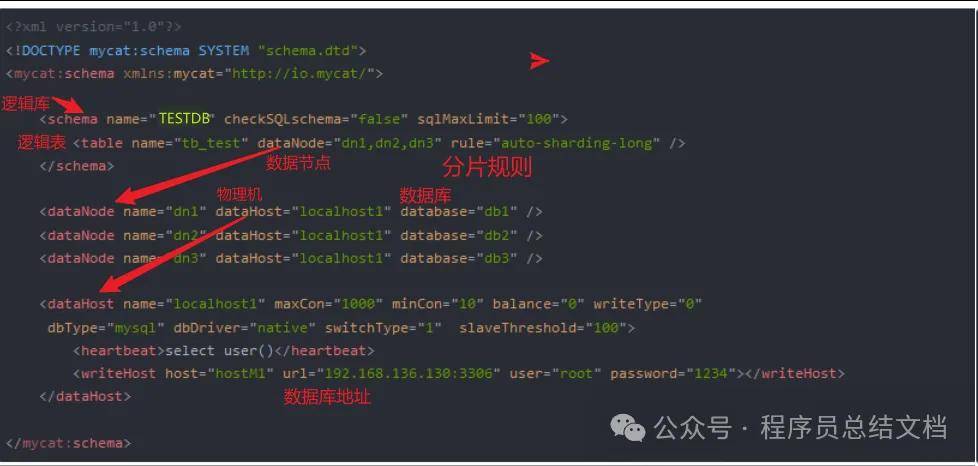
schema.xml 作为MyCat中重要的配置文件之一,**管理着MyCat的逻辑库、逻辑表以及对应的分片规则、DataNode以及DataSource。** 弄懂这些配置,是正确使用MyCat的前提。这里就一层层对该文件进行解析。
schema标签用于定义MyCat实例中的逻辑库Table 标签定义了MyCat中的逻辑表
rule用于指定分片规则
auto-sharding-long的分片规则是按ID值的范围进行分片 1-5000000 为第1片
5000001-10000000 为第2片.... 具体设置我们会在第5小节中讲解。dataNode 标签定义了MyCat中的数据节点,也就是我们通常说所的数据分片。dataHost标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。
修改schema.xml文件

3.2.2 配置文件server.xml
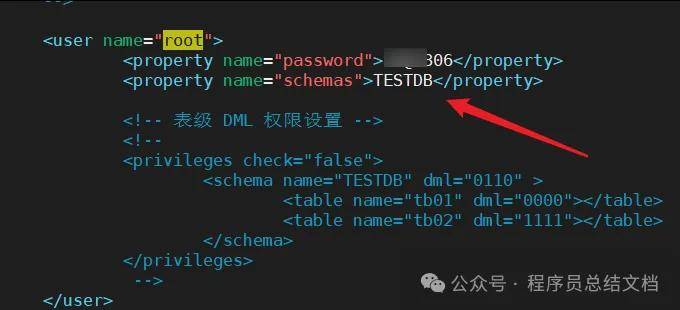
server.xml几乎保存了所有mycat需要的系统配置信息。最常用的是在此配置用户名、密码及权限。在system中添加UTF-8字符集设置,否则存储中文会出现问号
<property name="charset">utf8</property>
修改user的设置 , 我们这里为 ITCAST 设置了两个用户,这里的TESTDB逻辑库要和schema.xml中的逻辑库一致
<user name="test">
<property name="password">test</property>
<property name="schemas">TESTDB</property>
</user>
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
</user>
3.3 MyCat分片测试
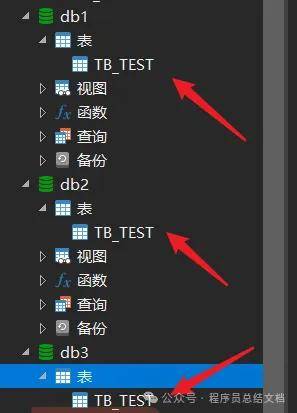
登录Mycat后,执行下列语句创建一个表,前提是你在schema.xml的逻辑表中有指定下表
CREATE TABLE TB_TEST (
id BIGINT(20) NOT NULL,
title VARCHAR(100) NOT NULL ,
PRIMARY KEY (id)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
测试改名后能否成功,发现失败,因此需要在schema.xml中指定逻辑表使用TB_TEST后创建成功,我们在查看MySQL的3个库,发现表都自动创建好啦。
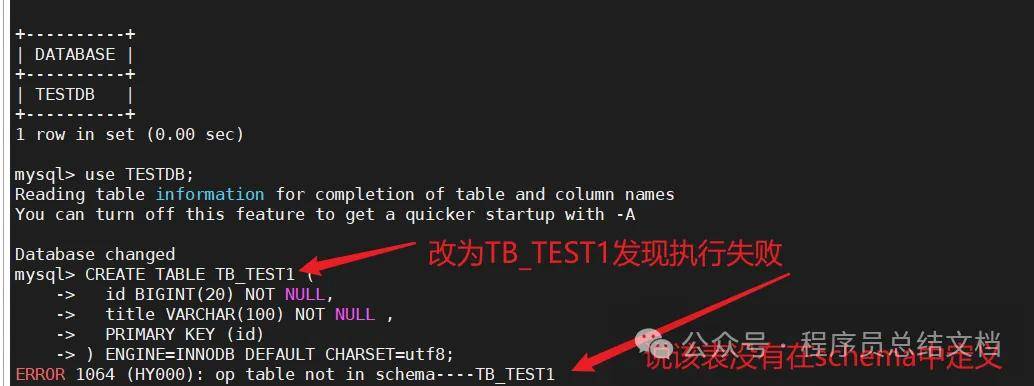
在这里插入图片描述
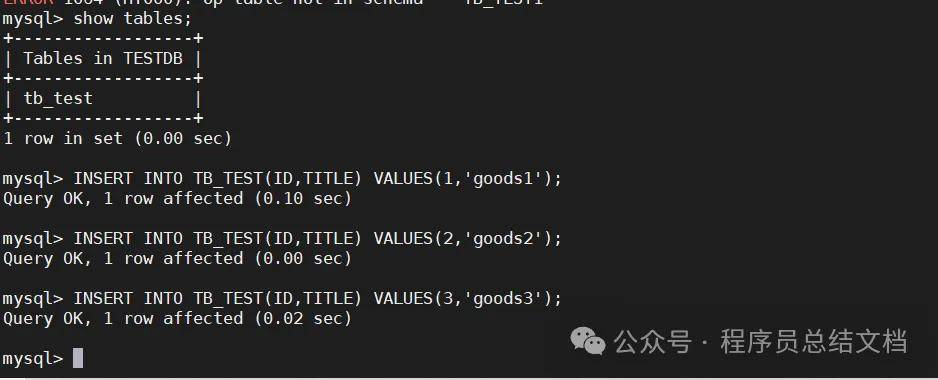
接下来是插入表数据,注意,在写 INSERT 语句时一定要写把字段列表写出来
INSERT INTO TB_TEST(ID,TITLE) VALUES(1,'goods1');
INSERT INTO TB_TEST(ID,TITLE) VALUES(2,'goods2');
INSERT INTO TB_TEST(ID,TITLE) VALUES(3,'goods3');
在这里插入图片描述
在这里插入图片描述
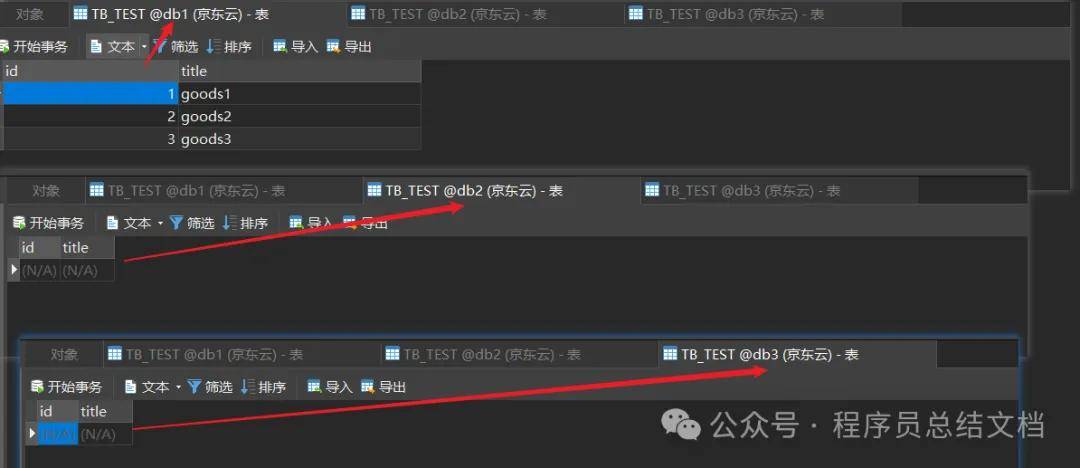
我们会发现这些数据被写入到第一个节点中了,那什么时候数据会写到第二个节点中呢?
我们插入下面的数据就可以插入第二个节点了
INSERT INTO TB_TEST(ID,TITLE) VALUES(5000001,'goods5000001');
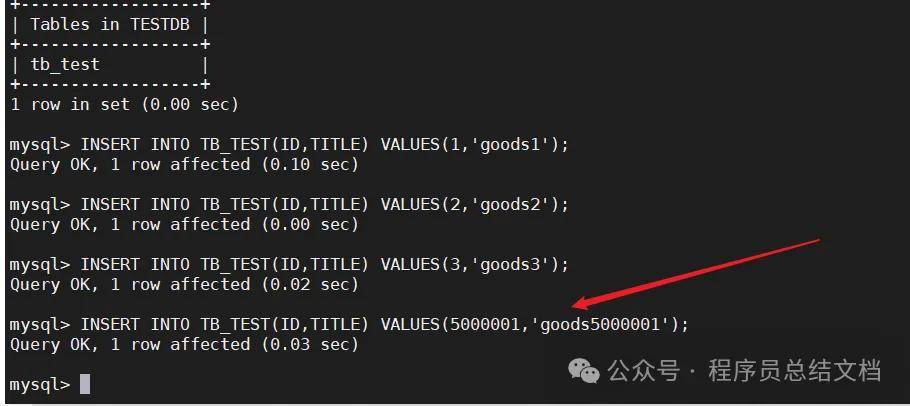

因为我们采用的分片规则是每节点存储500万条数据,所以当ID大于5000000则会存储到第二个节点上。目前只设置了两个节点,如果数据大于1000万条,会怎么样呢?执行下列语句测试一下
INSERT INTO TB_TEST(ID,TITLE) VALUES(10000001,'goods10000001');
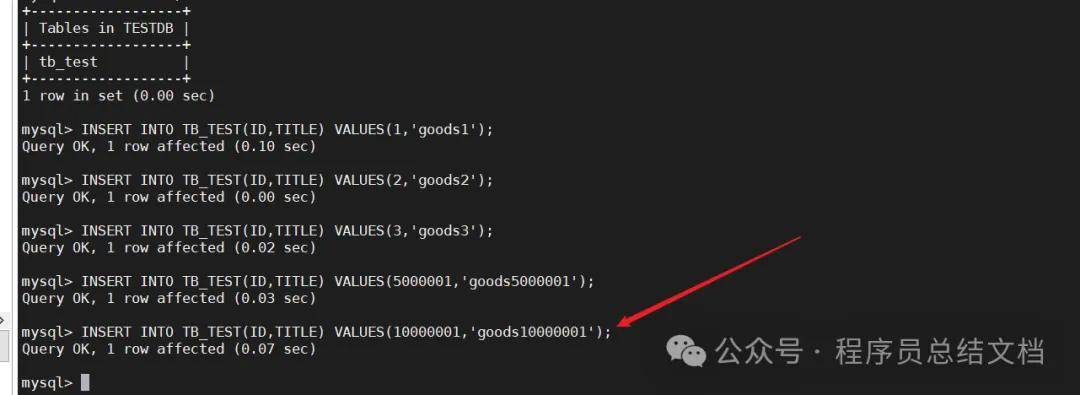
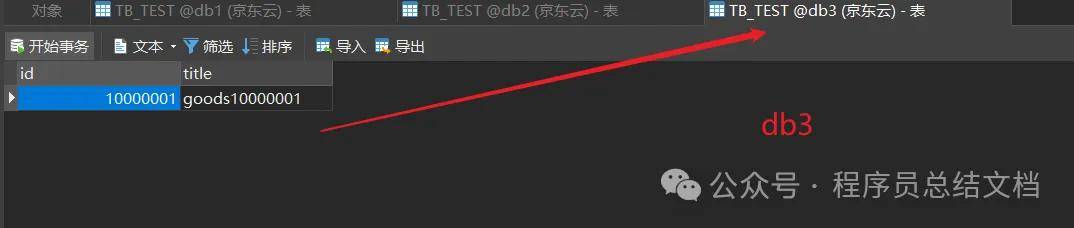
3.4 MyCat分片规则
3.4.1 按主键范围分片rang-long
通过上述测试证明,分片的规则是每张表存储500万的数据,那么这个数量可以修改吗?当然是可以的,请往下看
下图清晰的展示了规则的关联性
在这里插入图片描述
3.4.2 一致性哈希 murmur
当我们需要将数据平均分在几个分区中 ,需要使用一致性hash规则 我们找到function的name为 murmur 的定义,将count属性改为3,因为我要将数据分成3片
在rule.xml中配置如下:
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur" class="org.opencloudb.route.function.PartitionByMurmurHash">
<!-- 默认是0 -->
<property name="seed">0</property>
<!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="count">3</property>
<!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<property name="virtualBucketTimes">160</property>
<!-- 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="weightMapFile">weightMapFile</property> -->
<!-- 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property> -->
</function>
在schema.xml中配置逻辑表时,指定规则为sharding-by-murmur-order
<table name="tb_order" dataNode="dn1,dn2,dn3" rule="sharding-by-murmur-order" />
3.4.3 取模分片
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property>
</function>
id对count=3取模,结构肯定是0,1,2,因此根据结果放到3个库的其中一个
配置说明 :
属性描述columns标识将要分片的表字段algorithm指定分片函数与function的对应关系class指定该分片算法对应的类count数据节点的数量
在schema.xml中配置逻辑表时,指定规则为mod-long
<table name="tb_brand" dataNode="dn1,dn2,dn3" rule="mod-long" />
3.4.4 枚举分片
通过在配置文件中配置可能的枚举值, 指定数据分布到不同数据节点上, 本规则适用于按照省份或状态拆分数据等业务 , 配置如下:status是枚举值
<tableRule name="sharding-by-intfile">
<rule>
<columns>status</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
partition-hash-int.txt ,指定枚举指与节点索引的对应关系 内容如下 :
1=0
2=1
3=2
配置说明:
属性描述columns标识将要分片的表字段algorithm指定分片函数与function的对应关系class指定该分片算法对应的类mapFile对应的外部配置文件type默认值为0 ; 0 表示Integer , 1 表示StringdefaultNode默认节点 ; 小于0 标识不设置默认节点 , 大于等于0代表设置默认节点 ;
默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错 。
有趣
原文来源:https://mp.weixin.qq.com/s/zC0qTyIVI5ebs8VOjh9J9g
来源:本文内容搜集或转自各大网络平台,并已注明来源、出处,如果转载侵犯您的版权或非授权发布,请联系小编,我们会及时审核处理。
声明:江苏教育黄页对文中观点保持中立,对所包含内容的准确性、可靠性或者完整性不提供任何明示或暗示的保证,不对文章观点负责,仅作分享之用,文章版权及插图属于原作者。


联系邮箱:service#改成@jsedu114.com
地 址:中国●江苏
南京市秦淮区洪武路359号1506室
Copyright©2011-2025 JSedu114 All Rights Reserved. 江苏教育信息综合发布查询平台保留所有权利
![]() 苏公网安备32010402000125
苏ICP备14051488号-3技术支持:南京博盛蓝睿网络科技有限公司
苏公网安备32010402000125
苏ICP备14051488号-3技术支持:南京博盛蓝睿网络科技有限公司
南京思必达教育科技有限公司版权所有 百度统计




 新浪微博
新浪微博


