




话不多说,直接上手!场景用的数据库是mysql5.6,下面简单的介绍下场景课程表create table Course(c_id int PRIMARY KEY,name varchar(10))数据100条学生表:create table Student(id int PRIMARY KEY,na...
话不多说,直接上手!
场景
用的数据库是mysql5.6,下面简单的介绍下场景
课程表
create table Course(
c_id int PRIMARY KEY,
name varchar(10)
)
数据100条
学生表:
create table Student(
id int PRIMARY KEY,
name varchar(10)
)
数据70000条
学生成绩表SC
CREATE table SC(
sc_id int PRIMARY KEY,
s_id int,
c_id int,
score int
)
数据70w条
查询目的:
查找语文考100分的考生
查询语句:
select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )
执行时间:30248.271s
为什么这么慢?先来查看下查询计划:
EXPLAIN
select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )

发现没有用到索引,type全是ALL,那么首先想到的就是建立一个索引,建立索引的字段当然是在where条件的字段。
先给sc表的c_id和score建个索引
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);
再次执行上述查询语句,时间为: 1.054s
快了3w多倍,大大缩短了查询时间,看来索引能极大程度的提高查询效率,看来建索引很有必要,很多时候都忘记建索引了,数据量小的的时候压根没感觉,这优化感觉挺爽。
但是1s的时间还是太长了,还能进行优化吗,仔细看执行计划:

查看优化后的sql:
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
WHERE
< in_optimizer > (
`YSB`.`s`.`s_id` ,< EXISTS > (
SELECT
1
FROM
`YSB`.`SC` `sc`
WHERE
(
(`YSB`.`sc`.`c_id` = 0)
AND (`YSB`.`sc`.`score` = 100)
AND (
< CACHE > (`YSB`.`s`.`s_id`) = `YSB`.`sc`.`s_id`
)
)
)
)
补充:这里有网友问怎么查看优化后的语句
方法如下:
在命令窗口执行

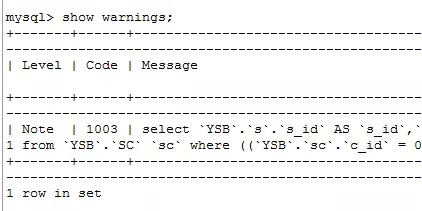
点击添加图片描述(最多60个字)
有type=all
按照笔者之前的想法,该sql的执行的顺序应该是先执行子查询
select s_id from SC sc where sc.c_id = 0 and sc.score = 100
耗时:0.001s
得到如下结果:
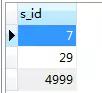
然后再执行
select s.* from Student s where s.s_id in(7,29,5000)
耗时:0.001s
这样就是相当快了啊,Mysql竟然不是先执行里层的查询,而是将sql优化成了exists子句,并出现了EPENDENT SUBQUERY,
mysql是先执行外层查询,再执行里层的查询,这样就要循环70007*11=770077次。
那么改用连接查询呢?
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100
这里为了重新分析连接查询的情况,先暂时删除索引sc_c_id_index,sc_score_index
执行时间是:0.057s
效率有所提高,看看执行计划:

这里有连表的情况出现,我猜想是不是要给sc表的s_id建立个索引
CREATE index sc_s_id_index on SC(s_id);
show index from SC
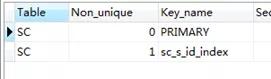
在执行连接查询
时间: 1.076s,竟然时间还变长了,什么原因?查看执行计划:

优化后的查询语句为:
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
JOIN `YSB`.`SC` `sc`
WHERE
(
(
`YSB`.`sc`.`s_id` = `YSB`.`s`.`s_id`
)
AND (`YSB`.`sc`.`score` = 100)
AND (`YSB`.`sc`.`c_id` = 0)
)
貌似是先做的连接查询,再执行的where过滤
回到前面的执行计划:
这里是先做的where过滤,再做连表,执行计划还不是固定的,那么我们先看下标准的sql执行顺序:

点击添加图片描述(最多60个字)
正常情况下是先join再where过滤,但是我们这里的情况,如果先join,将会有70w条数据发送join做操,因此先执行where
过滤是明智方案,现在为了排除mysql的查询优化,我自己写一条优化后的sql
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id
即先执行sc表的过滤,再进行表连接,执行时间为:0.054s
和之前没有建s_id索引的时间差不多
查看执行计划:

先提取sc再连表,这样效率就高多了,现在的问题是提取sc的时候出现了扫描表,那么现在可以明确需要建立相关索引
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);
再执行查询:
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id
执行时间为:0.001s,这个时间相当靠谱,快了50倍
执行计划:

我们会看到,先提取sc,再连表,都用到了索引。
那么再来执行下sql
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100
执行时间0.001s
执行计划:

这里是mysql进行了查询语句优化,先执行了where过滤,再执行连接操作,且都用到了索引。
总结:
1.mysql嵌套子查询效率确实比较低
2.可以将其优化成连接查询
3.建立合适的索引
4.学会分析sql执行计划,mysql会对sql进行优化,所以分析执行计划很重要
来源:本文内容搜集或转自各大网络平台,并已注明来源、出处,如果转载侵犯您的版权或非授权发布,请联系小编,我们会及时审核处理。
声明:江苏教育黄页对文中观点保持中立,对所包含内容的准确性、可靠性或者完整性不提供任何明示或暗示的保证,不对文章观点负责,仅作分享之用,文章版权及插图属于原作者。


联系邮箱:service#改成@jsedu114.com
地 址:中国●江苏
南京市秦淮区洪武路359号1506室
Copyright©2013-2024 JSedu114 All Rights Reserved. 江苏教育信息综合发布查询平台保留所有权利
![]() 苏公网安备32010402000125
苏ICP备14051488号-3技术支持:南京博盛蓝睿网络科技有限公司
苏公网安备32010402000125
苏ICP备14051488号-3技术支持:南京博盛蓝睿网络科技有限公司
南京思必达教育科技有限公司版权所有 百度统计




 新浪微博
新浪微博


