




我们都知道mybatis有一级,二级缓存之说。我们对他们的了解大部分都是这样:1,一级缓存对应SqlSession,二级缓存对应mapper。2,一级缓存默认开启,二级缓存需要手动开启3,当查询的时候,在二级缓存开...
我们都知道mybatis有一级,二级缓存之说。我们对他们的了解大部分都是这样:
1,一级缓存对应SqlSession,二级缓存对应mapper。
2,一级缓存默认开启,二级缓存需要手动开启
3,当查询的时候,在二级缓存开启的情况下查二级缓存,先查二级缓存,如果二级缓存也没有,然后查一级缓存,如果一级缓存再没有,则查数据库。查完数据库之后把数据放到缓存中。
那么,今天我们通过源码的方式来了解一下mybatis的缓存原理。
1,当我们走mapper1.selectOne(map);这行代码的时候:
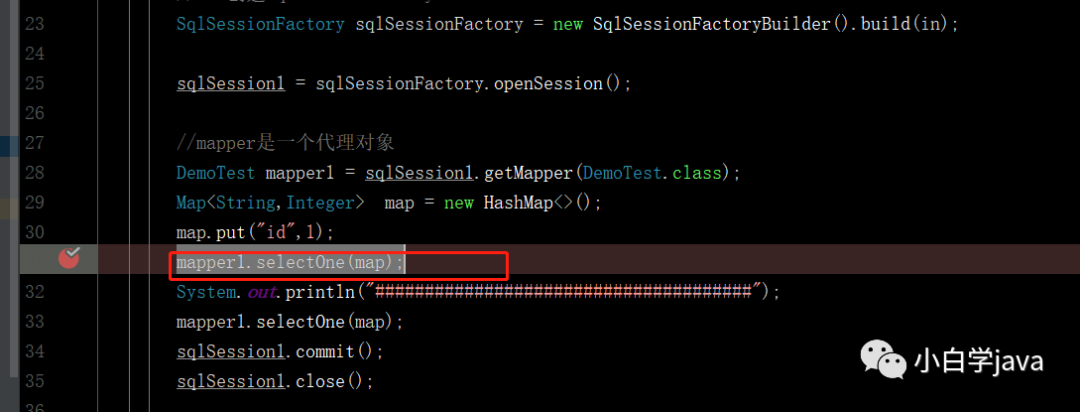
会通过代理的方式会走到下面第5代码executor.query()。
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) { try { MappedStatement ms = configuration.getMappedStatement(statement); //会先调用CachingExecutor子类的query return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); }}
我们就以这个executor作为切入点进入观察,跟进断点可知:这个executor会先使用他的子类CachingExecutor调用query(),这个类一看名字就知道跟缓存相关的。
我们来看这个CachingExecutor的query()方法:
@Overridepublic <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { //处理sql语句 BoundSql boundSql = ms.getBoundSql(parameterObject); //创建缓存key CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); //通过这个key作为缓存进行调用query方法 return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
这里其中如何创建这个CacheKey等会再说,我们先看看query()
@Overridepublic <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // ms.getCache()拿到缓存对象 开启二级缓存菜回进入if里面 Cache cache = ms.getCache(); if (cache != null) { flushCacheIfRequired(ms); //如果标签中设置useCache=false,那么不使用二级缓存 if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list; } } //如果不开启直接走下面这条查询,其实这条查询跟13行是一样的。 return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
这个MappedStatement.getCache()就是我们说的二级缓存。同时它会判断我们的二级缓存是否开启ms.isUseCache()。
那么它是如何初始化二级缓存并且如何设置isUseCache的呢?
这就回到我们解析配置文件说起(之前写过一次mybatis的执行流程,不清楚可以去看看,这里只是略讲):
1,在解析的时候会先后调用两个方法,如图:
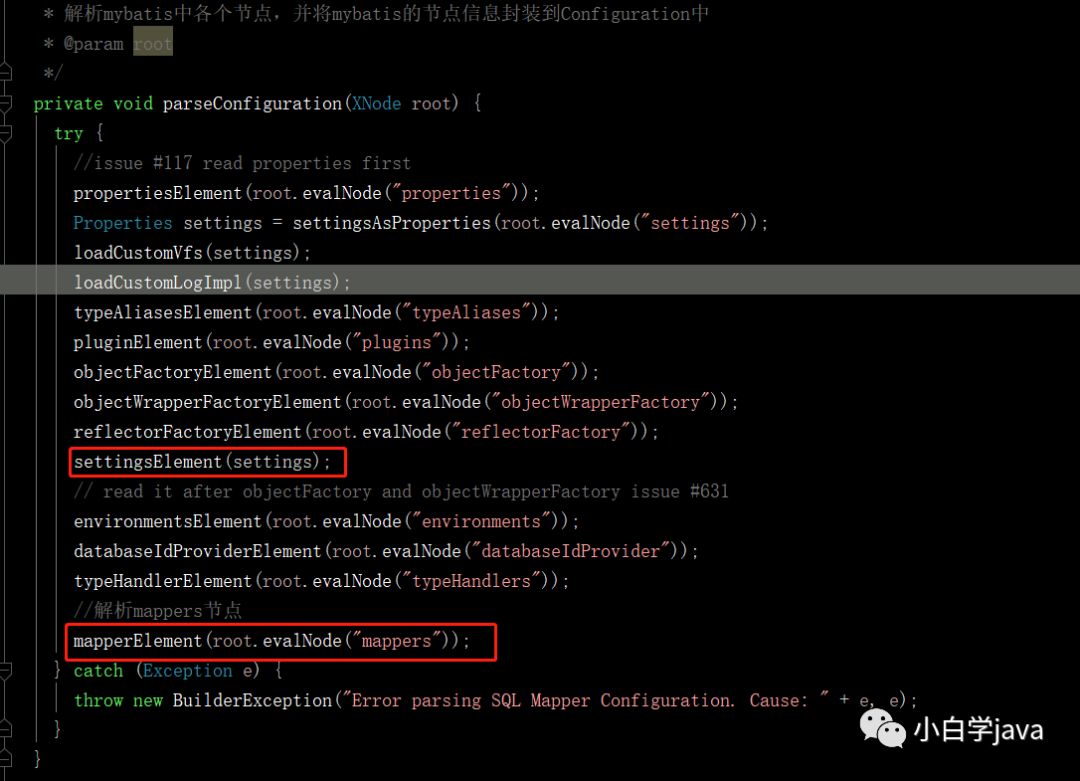
在settingsElement方法中,默认对mybatis配置文件是否启用二级缓存功能设置true。有人就奇怪了,二级缓存不是默认不开启吗,怎么默认为true?不要着急。。
然后是mapperElement方法中,看调用的mapperParser.parse()的方法
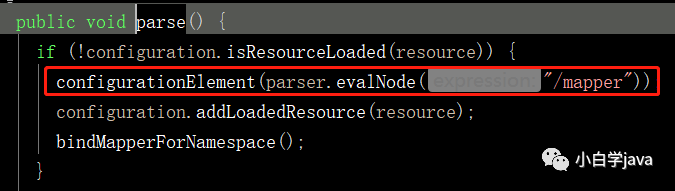
我们在点进去看configurationElement这个方法:
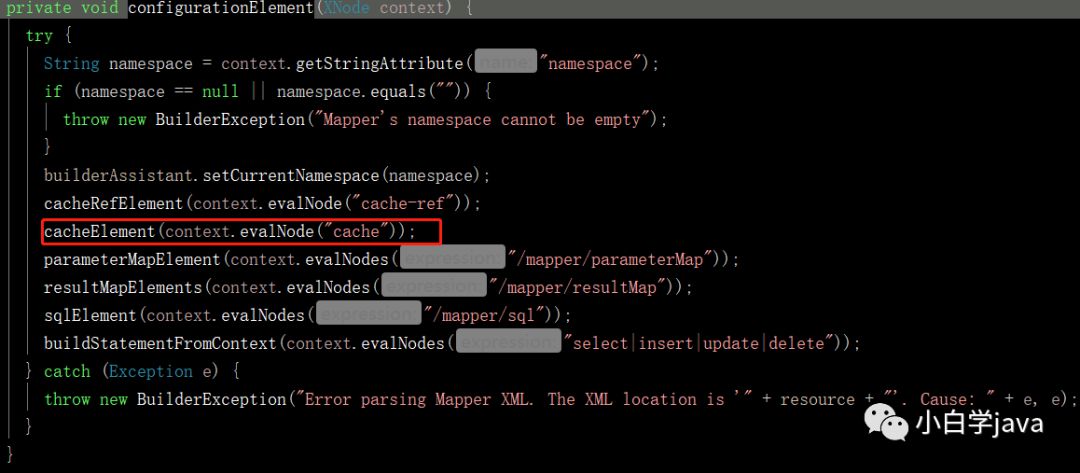
这个cacheElement()方法就是解析我们映射文件是否配置了<cache/>
如果不配置,那么什么也不做。也就是整个mapper中不开启二级缓存!
这我们就说明了Cache cache = ms.getCache();的由来
那么还有一个问题就是这个判断ms.isUseCache(),这个有什么用呢?也就是mapper虽然开启了二级缓存,它还要看看,select标签中是否禁用了二级缓存,默认如果不配置,那么为true,以下图中代码。

而如果配置为false了,将不会走
if (ms.isUseCache() && resultHandler == null){ //.......}
这个分支的代码,也就是不使用二级缓存。
讲到这里,大家应该明白为何二级缓存需要手动开启了吧?默认情况下,mybatis配置文件开启二级缓存,而mapper映射文件默认是关闭二级缓存的,简单的说配置文件开启了,可是我映射文件没有开启,那么还是不开启,所以我们说的开启二级缓存其实就是在映射文件中开启。当我们在映射文件中开启了二级缓存,那么映射文件中的select标签也是默认开启二级缓存的,我们可以通过这种机制来使某个select禁用二级缓存(在select标签中加入useCache=false即可)。
2)继续说CachingExecutor.query()方法。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { Cache cache = ms.getCache(); if (cache != null) { flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list; } } return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
如果开启二级缓存,则直接当我们进入二级缓存的逻辑之中,tcm.getObject(cache, key)这个就是根据key从缓存中拿,如果拿不到,则调用这个delegate.query()方法拿。
if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, boundSql); @SuppressWarnings("unchecked") //从缓存中拿数据 List<E> list = (List<E>) tcm.getObject(cache, key); //判断是否拿到,如果拿不到则delegate.query( if (list == null) { list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list;}
以上就是mybatis二级缓存中获取数据的逻辑
我们再来看看delegate.query()这个方法:
通过代码我们发现,如果没有开启二级缓存,或者二级缓存中没有数据
那么最后都是执行delegate.query()方法。
这个方法由Executor的子类BaseExecutor来调用它的query方法:
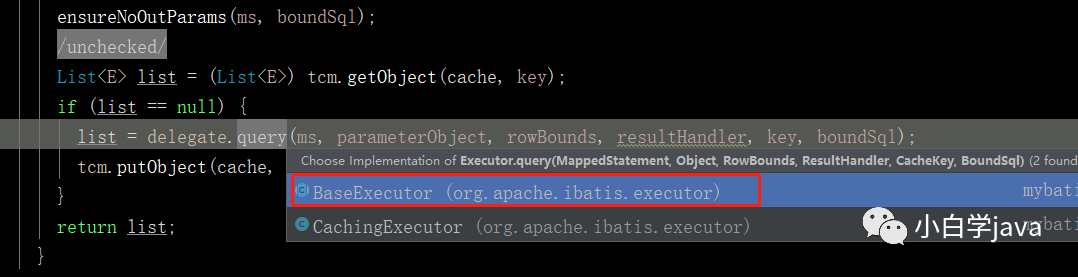
那么我们看看里面是什么:
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List<E> list; try { queryStack++; //同样,先从缓存中拿 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { //处理本地缓存的输出参数 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { //如果缓存拿不到则查询数据库 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } //.... return list;}
这个代码就很好了,跟之前差不多,13行就是从缓存中拿,如果拿不到,那么就直接从18行中从数据库中拿。这就是从一级缓存中拿数据的流程。
这就是mybatis查询语句从缓存获取数据的流程。
那么这个缓存对象到底是什么??
我们可以开启二级缓存,然后通过CachingExecutor的query()打断点进入看看Cache cache = ms.getCache();这个是什么。

这样,我们就能找到LruCache这个Cache了。
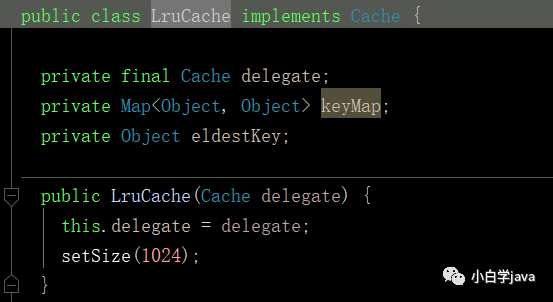
这个LruCache有个成员变量:private final Cache delegate;我们可以通过之前看出他就是一个PerpetualCache类,

到这里就不难看出,不管是一级缓存还是二级缓存,他们的缓存设计思想都是Map。
既然我们懂了缓存其实就是个map,那么如何确定key呢??
这就是之前没有说的CacheKey,也就是下面代码的第5行
@Overridepublic <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameterObject); // 确定key,如何确定? CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
createCacheKey同样是由BaseExecutor进行调用createCacheKey()方法。

我们最后再看看它的实现逻辑:
它就是通过一系列的update语句来确认CacheKey,具体如下:
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) { if (closed) { throw new ExecutorException("Executor was closed."); } CacheKey cacheKey = new CacheKey(); //确定cacheKey 的逻辑如下 cacheKey.update(ms.getId());//通过mapper中的select标签id cacheKey.update(rowBounds.getOffset());//跟分页有关,不用理 cacheKey.update(rowBounds.getLimit());//跟分页有关,不用理 cacheKey.update(boundSql.getSql());//通过sql语句 //省略代码 return cacheKey;}
那么update方法中到底如何实现?
public void update(Object object) { int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object); count++; checksum += baseHashCode; baseHashCode *= count; hashcode = multiplier * hashcode + baseHashCode; updateList.add(object);}
看到HashCode就明白了update就是通过哈希算法来确认CacheKey的。
我们明白了select的过程以及使用缓存的原理,那么update呢?其实好多人都知道mybatis在执行update,insert,delete之后,都会清空缓存。
因为在执行update,insert,delete的过程中,最后都是BaseExecutor调用update方法,所以我们只要看这个代码
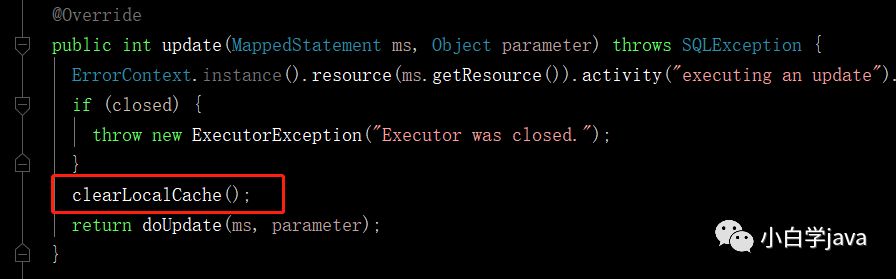
这个就是清空缓存的代码。
以上就是原理,最后我们通过select执行打印的sql的例子来看看效果:
1,关闭二级缓存:
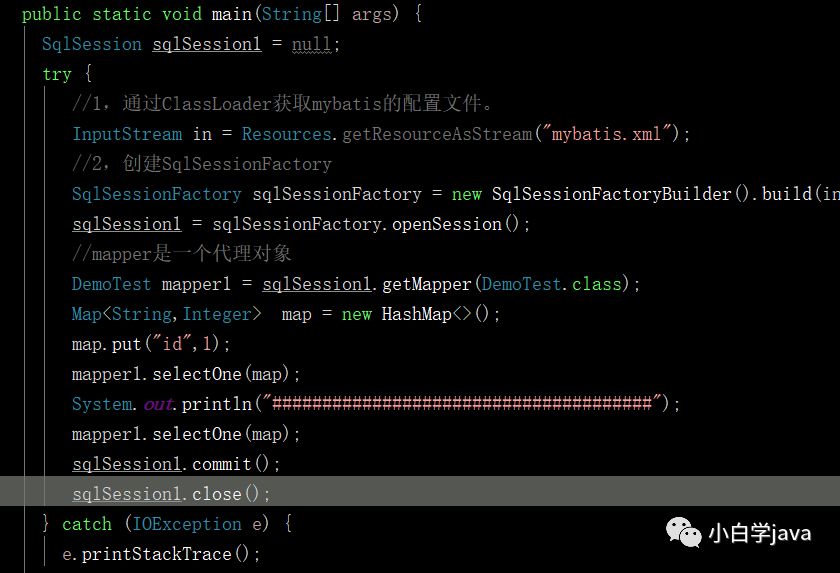
效果:两次一样的查询只发出一条sql
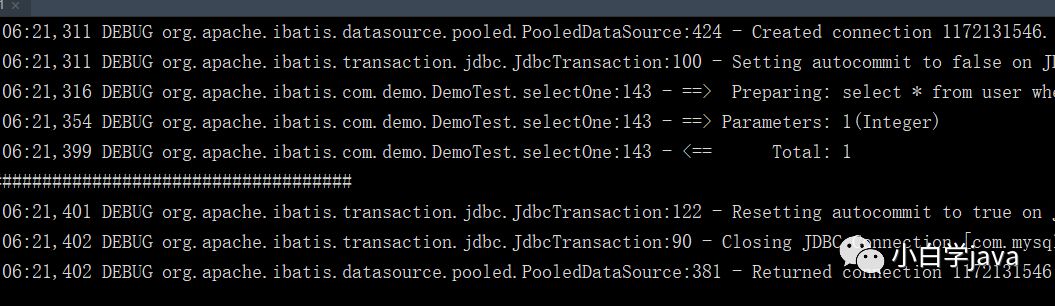
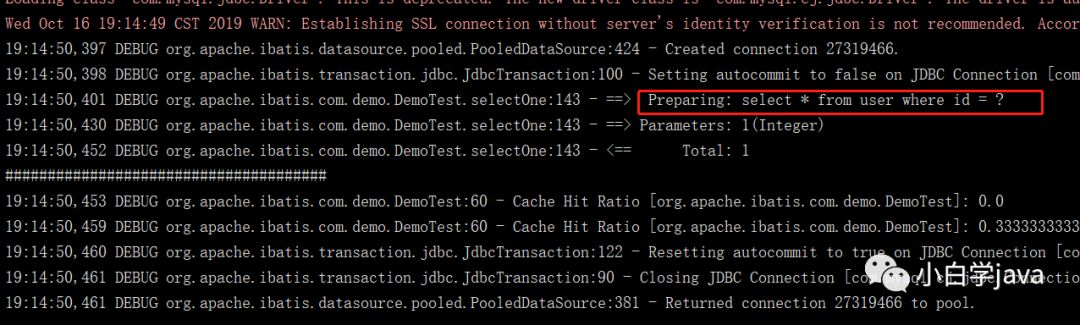
2,开启二级缓存:
结果:同样只发出一条sql
总结:
1,二级缓存需要手动开启,其实就是只用在映射文件中加入<cache/>。因为mybatis配置文件已经默认开启了二级缓存。
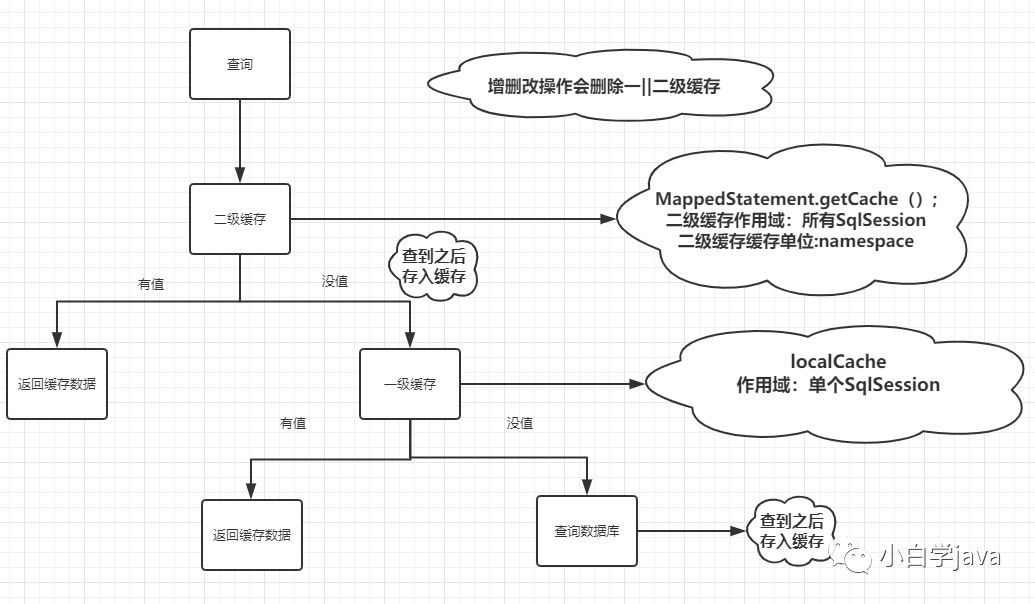
2,发出select语句之后,如果开启二级缓存,先在二级缓存中查数据。如果查不到数据,则查一级缓存,如果查不到,则最后查数据库。
3,insert,update,delete执行后,会清空缓存,不管是一级还是二级缓存
4,缓存对象Cache其实就是Map来实现的
5,缓存的key分别由select标签id,分页信息,sql通过一系列哈希算法来确定
最后附上Mybatis缓存执行流程:
本人水平有限,难免有错误或遗漏之处,望大家指正和谅解,提出宝贵意见,愿与之交流。
来源:本文内容搜集或转自各大网络平台,并已注明来源、出处,如果转载侵犯您的版权或非授权发布,请联系小编,我们会及时审核处理。
声明:江苏教育黄页对文中观点保持中立,对所包含内容的准确性、可靠性或者完整性不提供任何明示或暗示的保证,不对文章观点负责,仅作分享之用,文章版权及插图属于原作者。


联系邮箱:service#改成@jsedu114.com
地 址:中国●江苏
南京市秦淮区洪武路359号1506室
Copyright©2013-2024 JSedu114 All Rights Reserved. 江苏教育信息综合发布查询平台保留所有权利
![]() 苏公网安备32010402000125
苏ICP备14051488号-3技术支持:南京博盛蓝睿网络科技有限公司
苏公网安备32010402000125
苏ICP备14051488号-3技术支持:南京博盛蓝睿网络科技有限公司
南京思必达教育科技有限公司版权所有 百度统计




 新浪微博
新浪微博


